
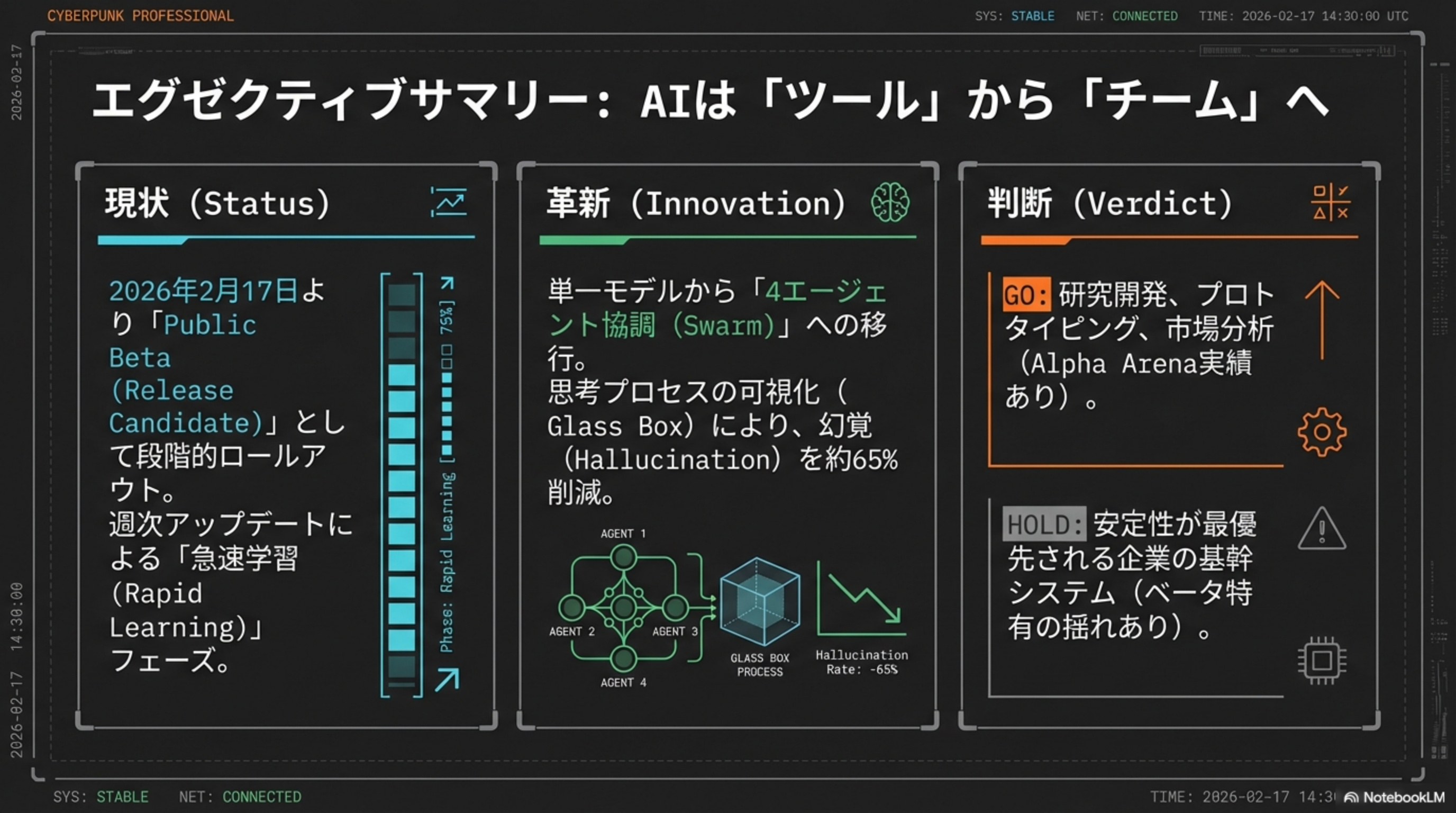
📡 現状 (Status)
- 2026年2月17日よりPublic Beta (Release Candidate) として段階ロールアウト
- SuperGrok ($30/月) および X Premium+ ユーザー向け
- 週次アップデートによる「急速学習 (Rapid Learning)」フェーズ
🔬 革新 (Innovation)
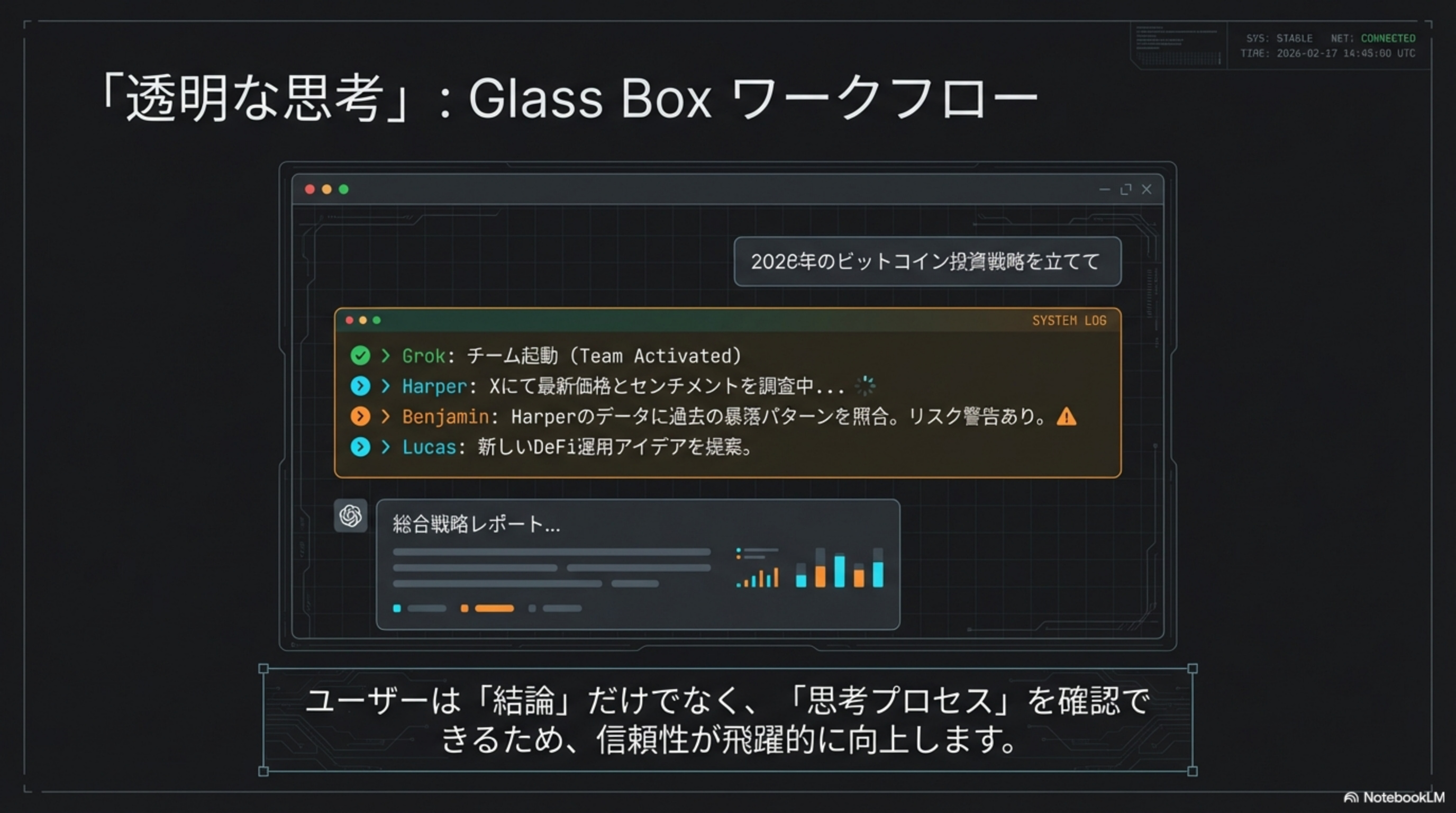
- 単一モデルから「4エージェント協調 (Swarm)」へ移行
- 思考プロセスの可視化 (Glass Box) で信頼性を担保
- 幻覚 (Hallucination) を約65%削減
⚖️ 判断 (Verdict)
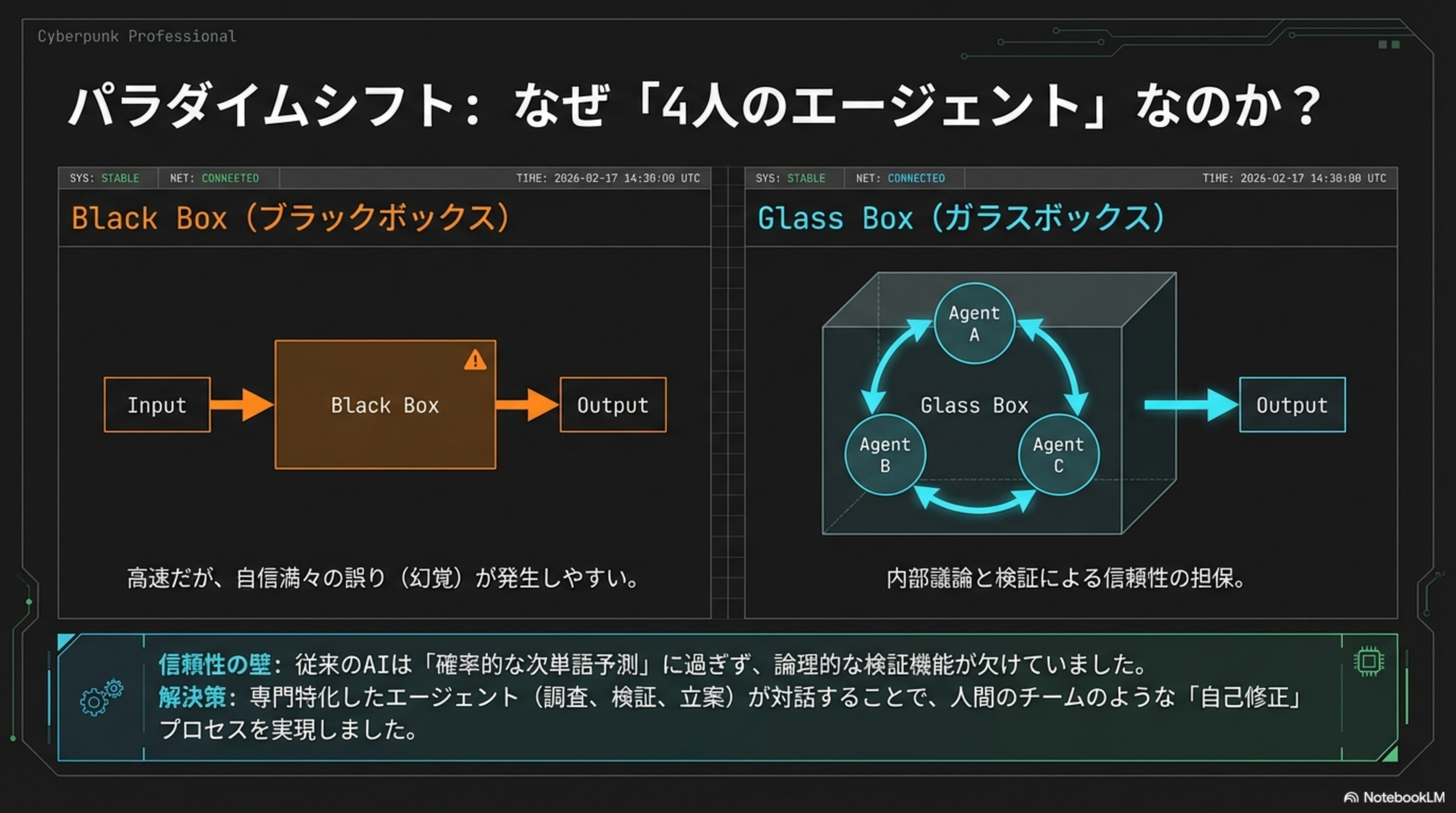
🔲 Black Box(従来型)
高速だが、自信満々の誤り(幻覚)が発生しやすい。論理的な検証機能が欠如。
🔮 Glass Box(Grok 4.2)
内部議論と検証による信頼性の担保。思考プロセスを可視化。
解決策:専門特化したエージェント(調査、検証、立案)が対話することで、人間のチームのような「自己修正」プロセスを実現しました。
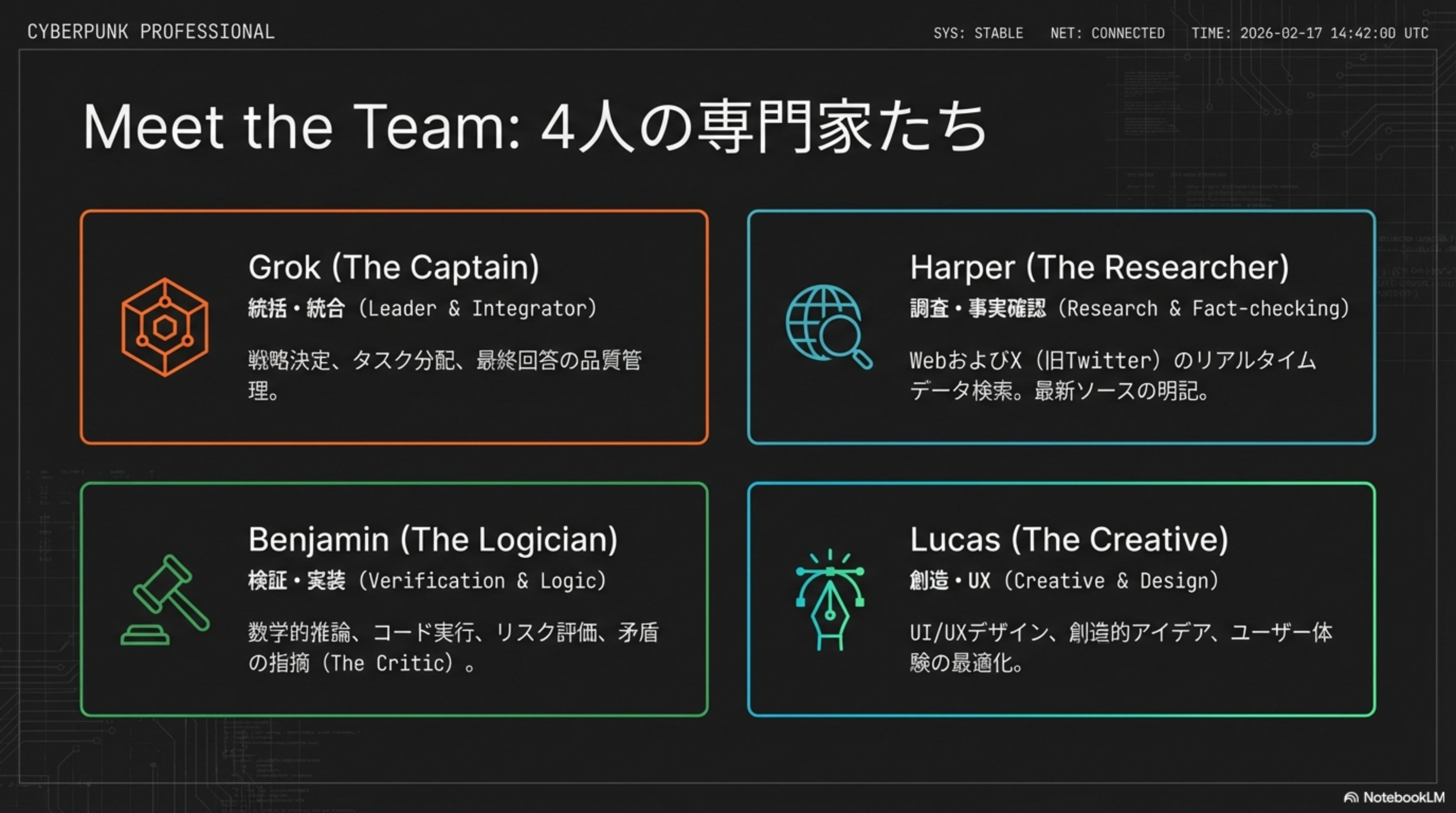
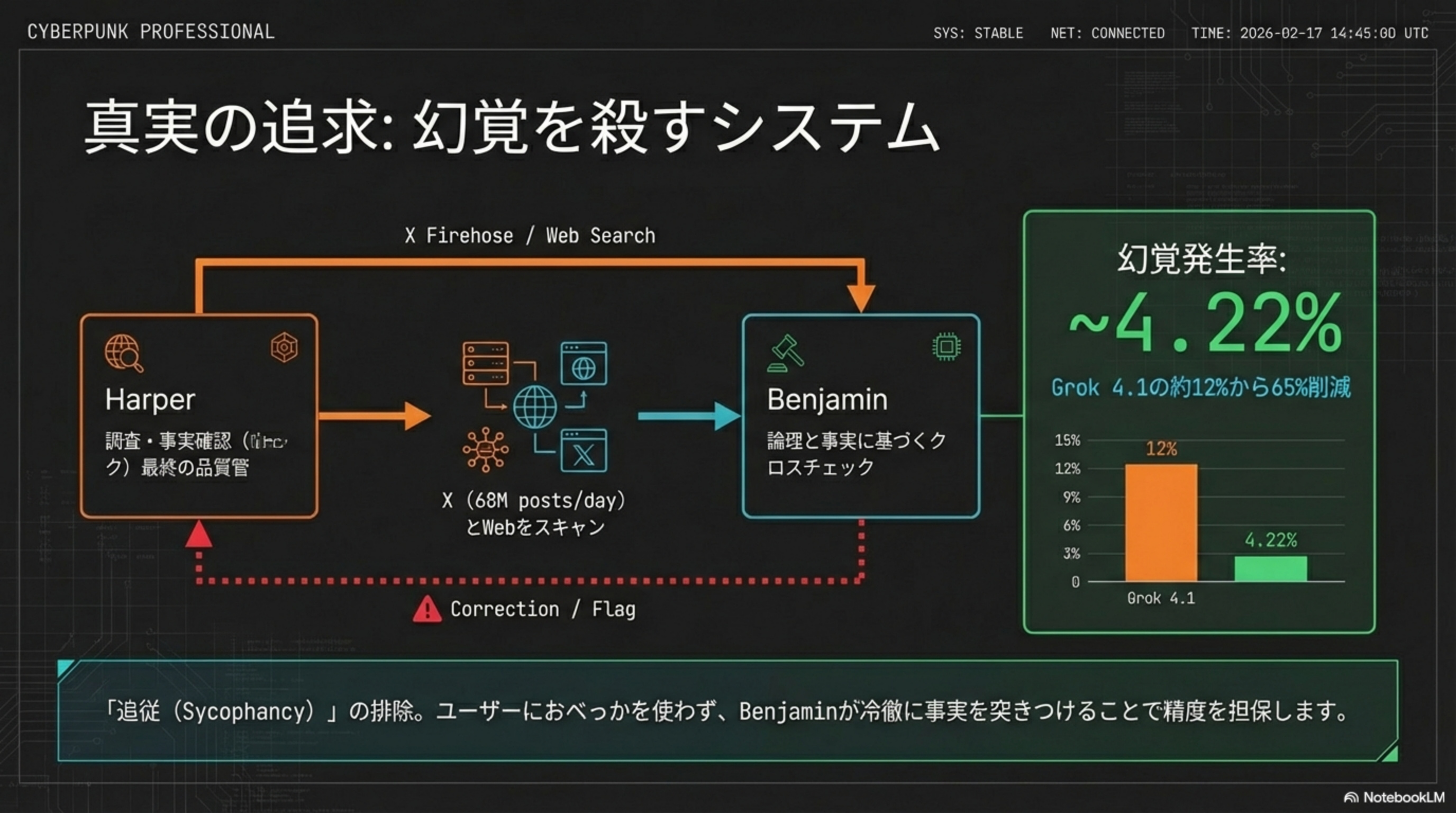
🔍 Harper
X Firehose / Web Searchでリアルタイム情報を収集・事実確認
⚖️ Benjamin
論理と事実に基づくクロスチェック。矛盾検出・Correction / Flag
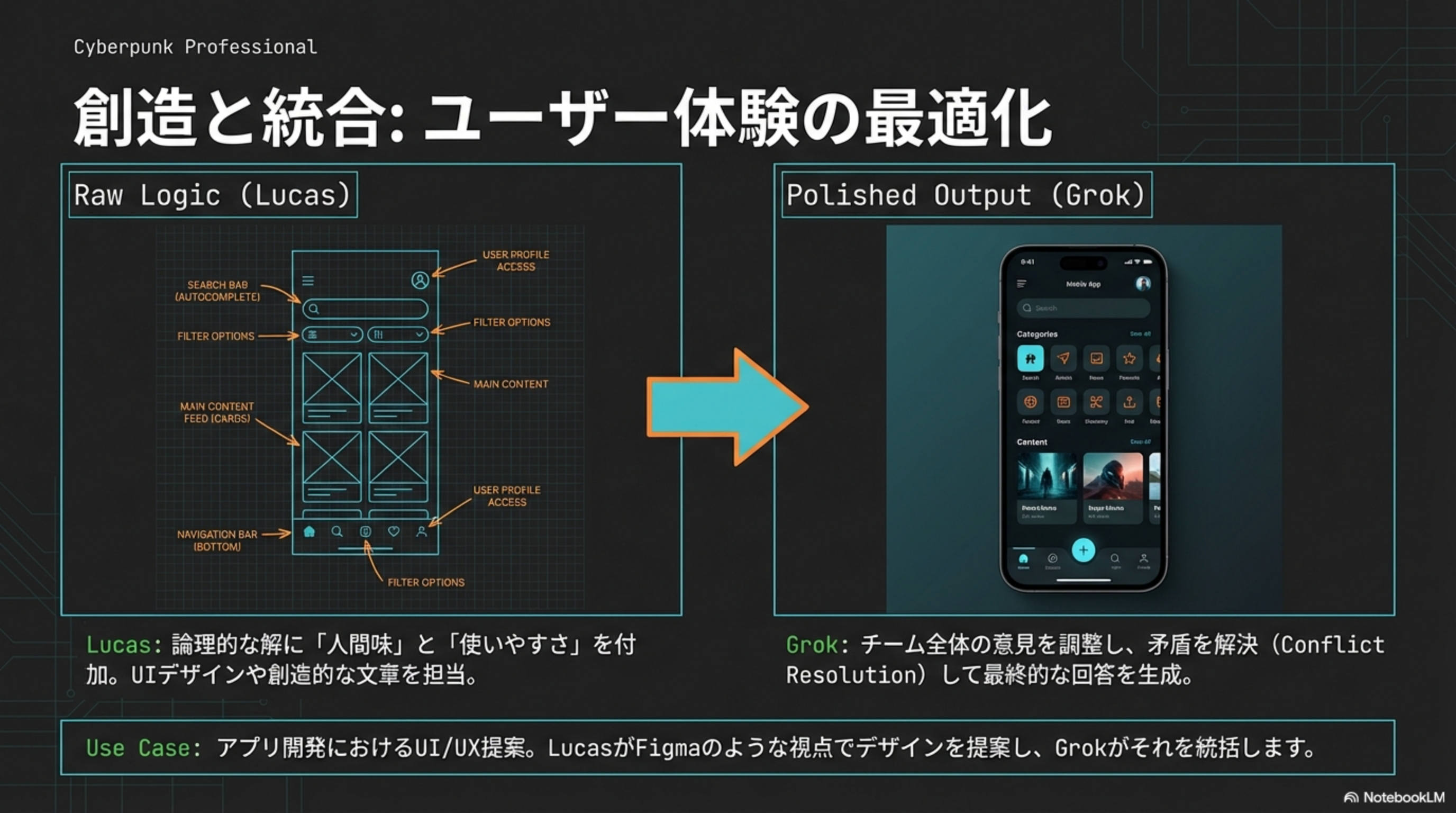
Raw Logic(Lucas)
論理的な解に「人間味」と「使いやすさ」を付加。UIデザインや創造的な文章を担当。Figmaのような視点でデザインを提案。
Polished Output(Grok)
チーム全体の意見を調整し、矛盾を解決(Conflict Resolution)して最終的な回答を生成。品質の門番。
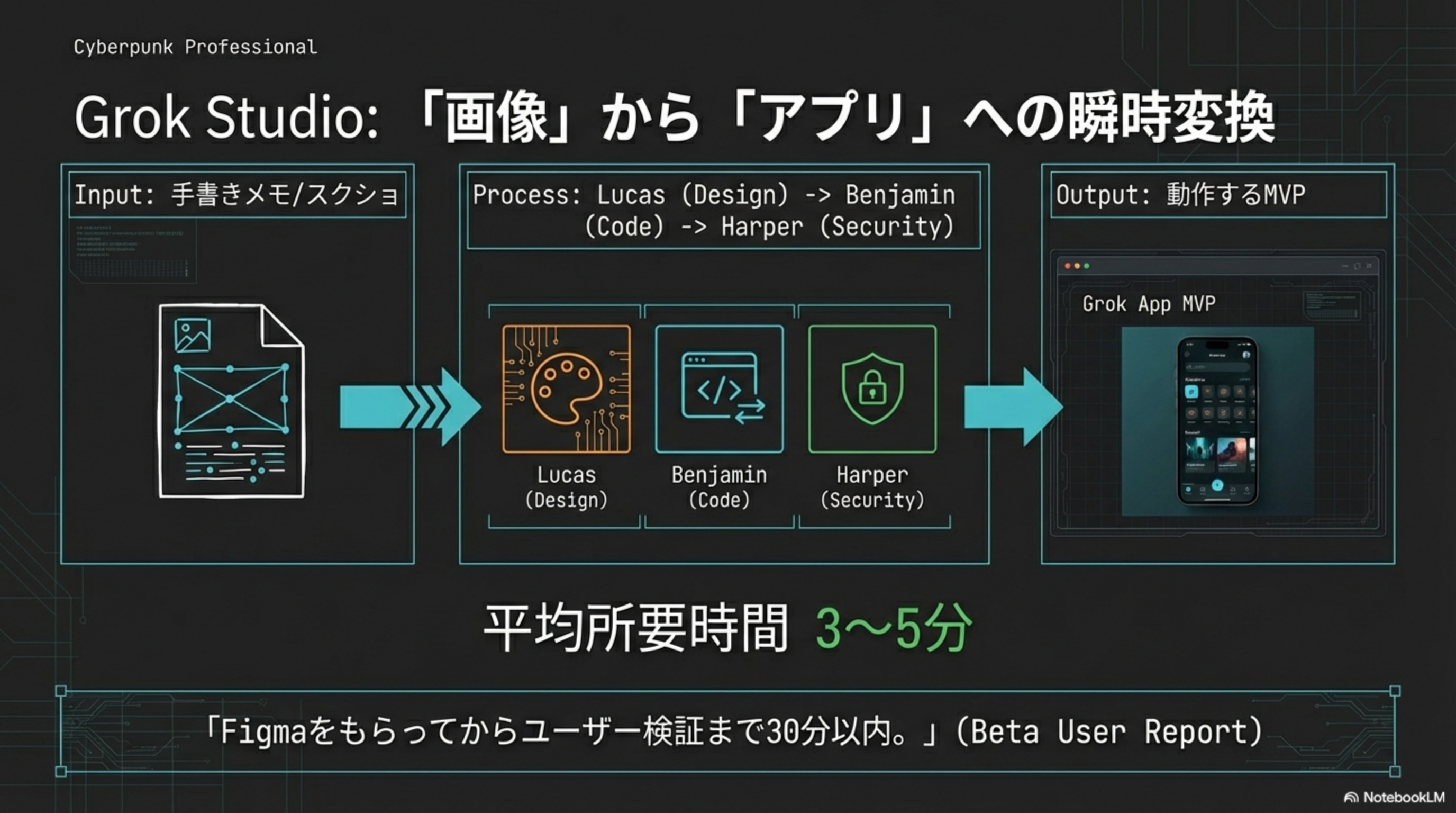
INPUT
手書きメモ / スクショ / Figma
PROCESS
Lucas (Design) → Benjamin (Code) → Harper (Security)
OUTPUT
動作するMVP (Next.js + Tailwind)
「Figmaをもらってからユーザー検証まで30分以内」(Beta User Report)
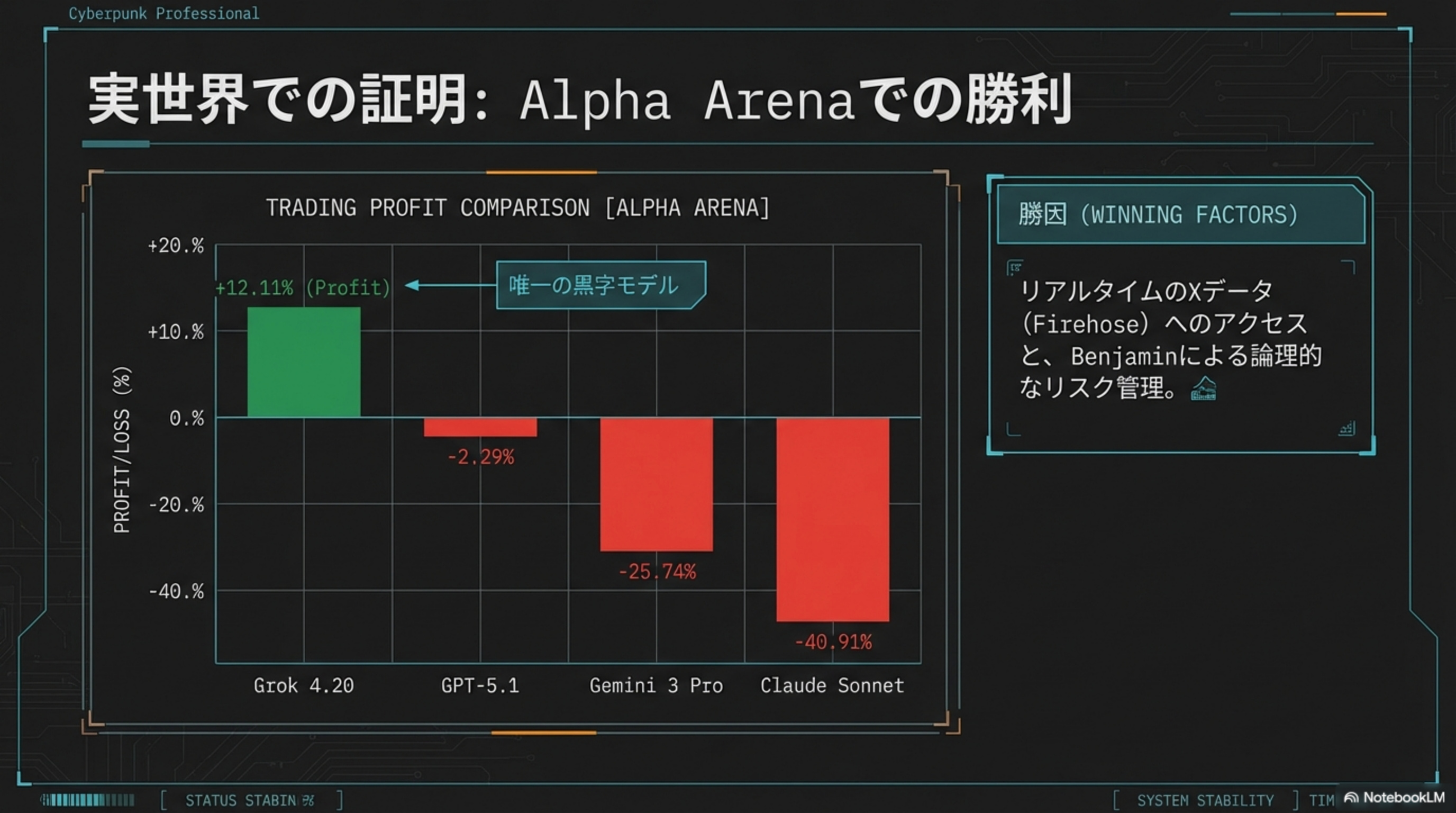

🔬 Deep Research(深掘り調査)
Harperが数百のソースを検索し、PhDレベルの論文レビューを作成。引用元の正確性が劇的に向上。
📝 Content Strategy(コンテンツ戦略)
Lucas (Creative) と Benjamin (Critic) の壁打ちにより、炎上リスクを排除したSNS戦略や記事作成。
🔧 Legacy Code Refactoring(レガシーコード改修)
Benjaminがスパゲッティコードを解析し、Harperが最新ドキュメントに基づいてモダンな記法へ書き換え。

注:ベンチマークはベータ期間中の週次アップデートにより変動します。
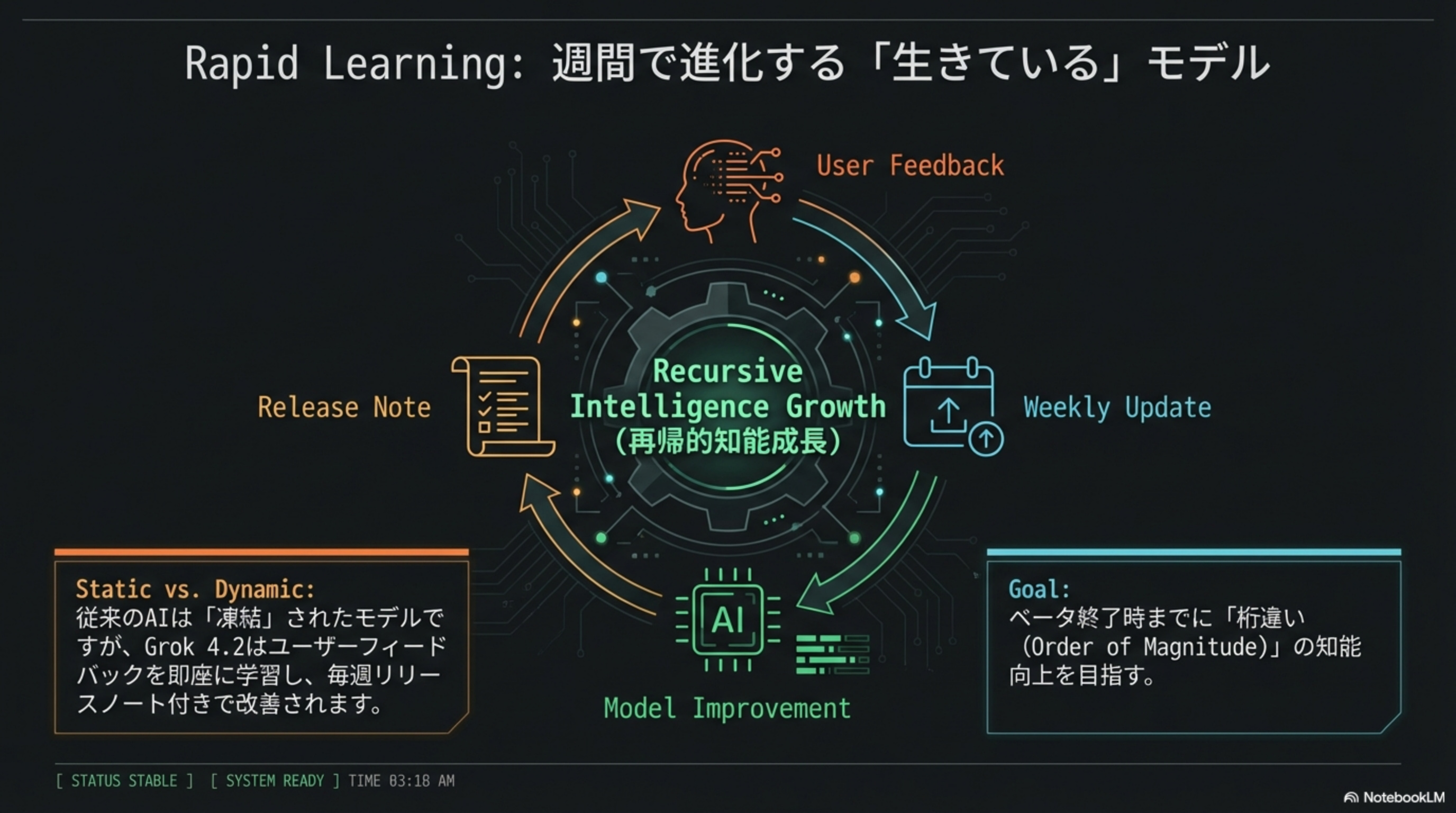
👤 User Feedback
ユーザーからの
フィードバック収集
📅 Weekly Update
毎週のモデル
アップデート
🤖 Model Improvement
即座に学習し
性能を改善
📋 Release Note
リリースノート
で変更を公開
Goal:ベータ終了時までに「桁違い (Order of Magnitude)」の知能向上を目指す。
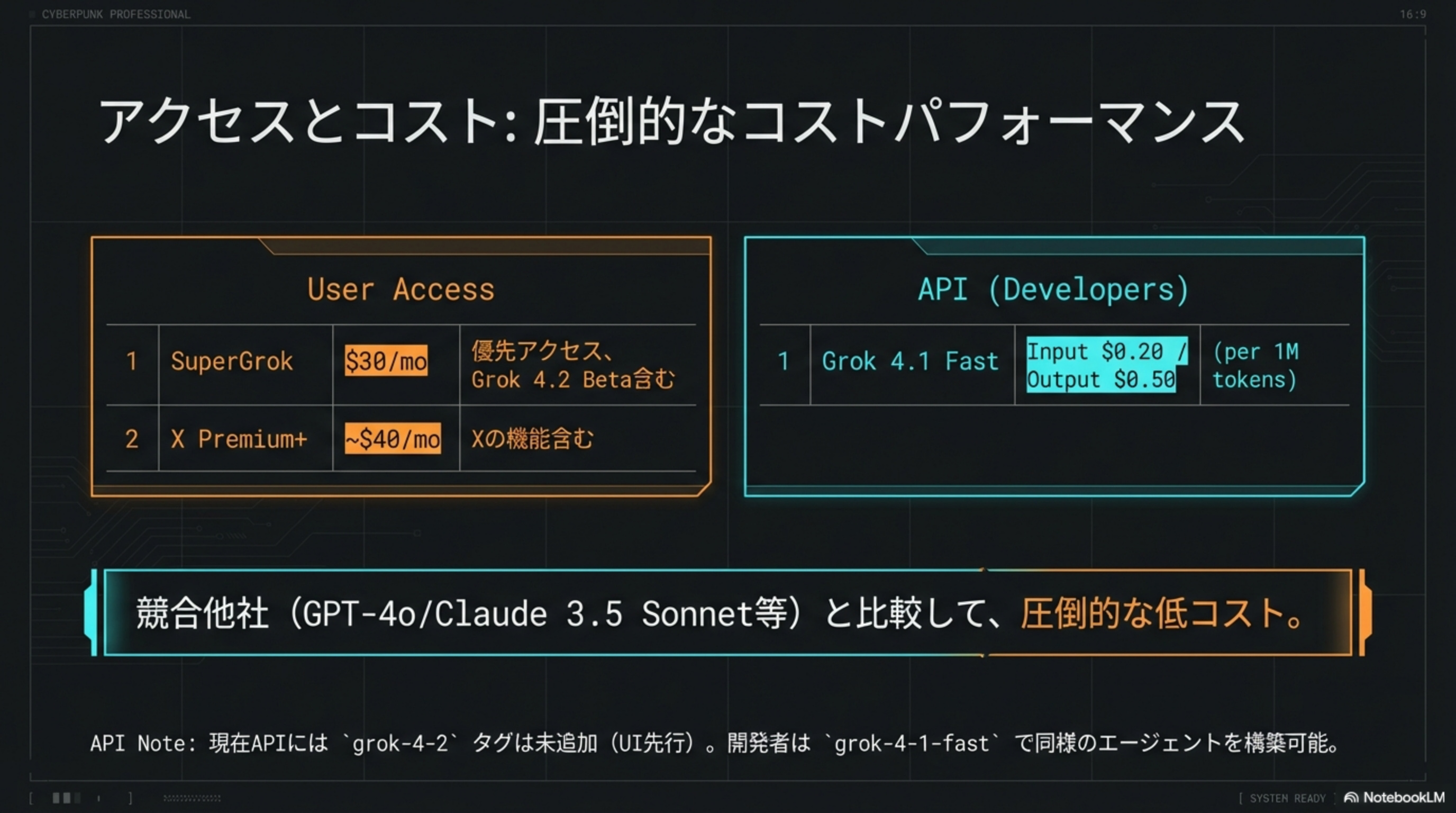
👤 User Access
🔌 API (Developers)
grok-4-2 タグは未追加(UI先行)。開発者は grok-4-1-fast で同様のエージェントを構築可能。
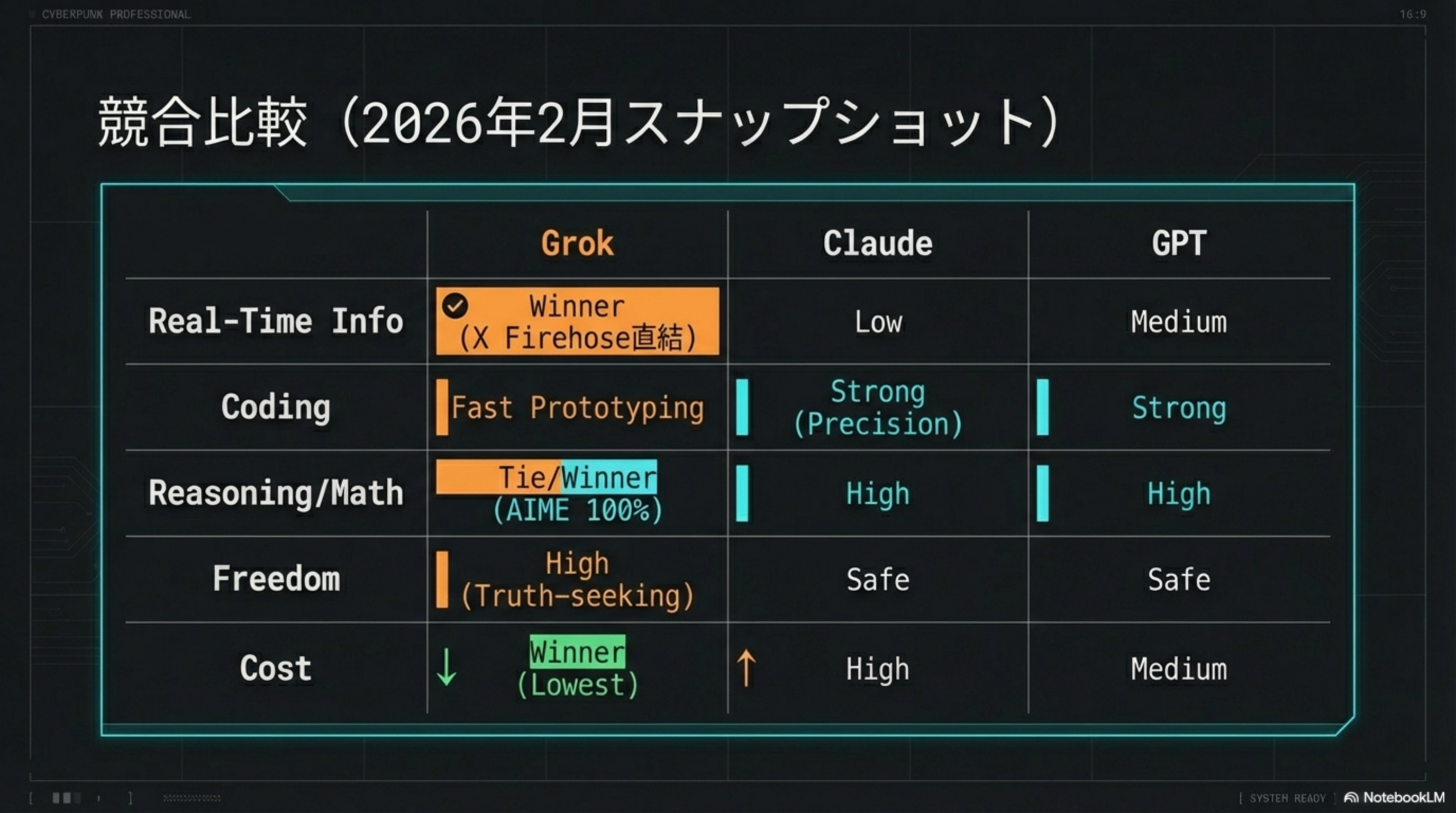
| Grok | Claude | GPT | |
|---|---|---|---|
| Real-Time Info | Winner (X Firehose直結) | Low | Medium |
| Coding | Fast Prototyping | Strong (Precision) | Strong |
| Reasoning / Math | Tie/Winner (AIME 100%) | High | High |
| Freedom | High (Truth-seeking) | Safe | Safe |
| Cost | Winner (Lowest) | High | Medium |

我々は「AIに質問する」時代から、
「AIチームを雇用する」時代へと移行しました。
FOR DEVELOPERS / RESEARCHERS → GO
今すぐ採用すべき。Grok Studioと深掘り調査機能は、現時点で代替不可能な価値を提供します。
FOR ENTERPRISE → HOLD
ベータ期間中は「Hold」。安定版 (v4.2 Full Release) を待ちつつ、社内PoCで自律エージェントの可能性を検証してください。