DeepSeek-V3.2の登場:長文処理とコスト効率の劇的進化
DeepSeek-V3.2は、「DeepSeek Sparse Attention (DSA)」により計算量を劇的に削減。128Kトークン処理を実用化し、コストを破壊的に低減しました。
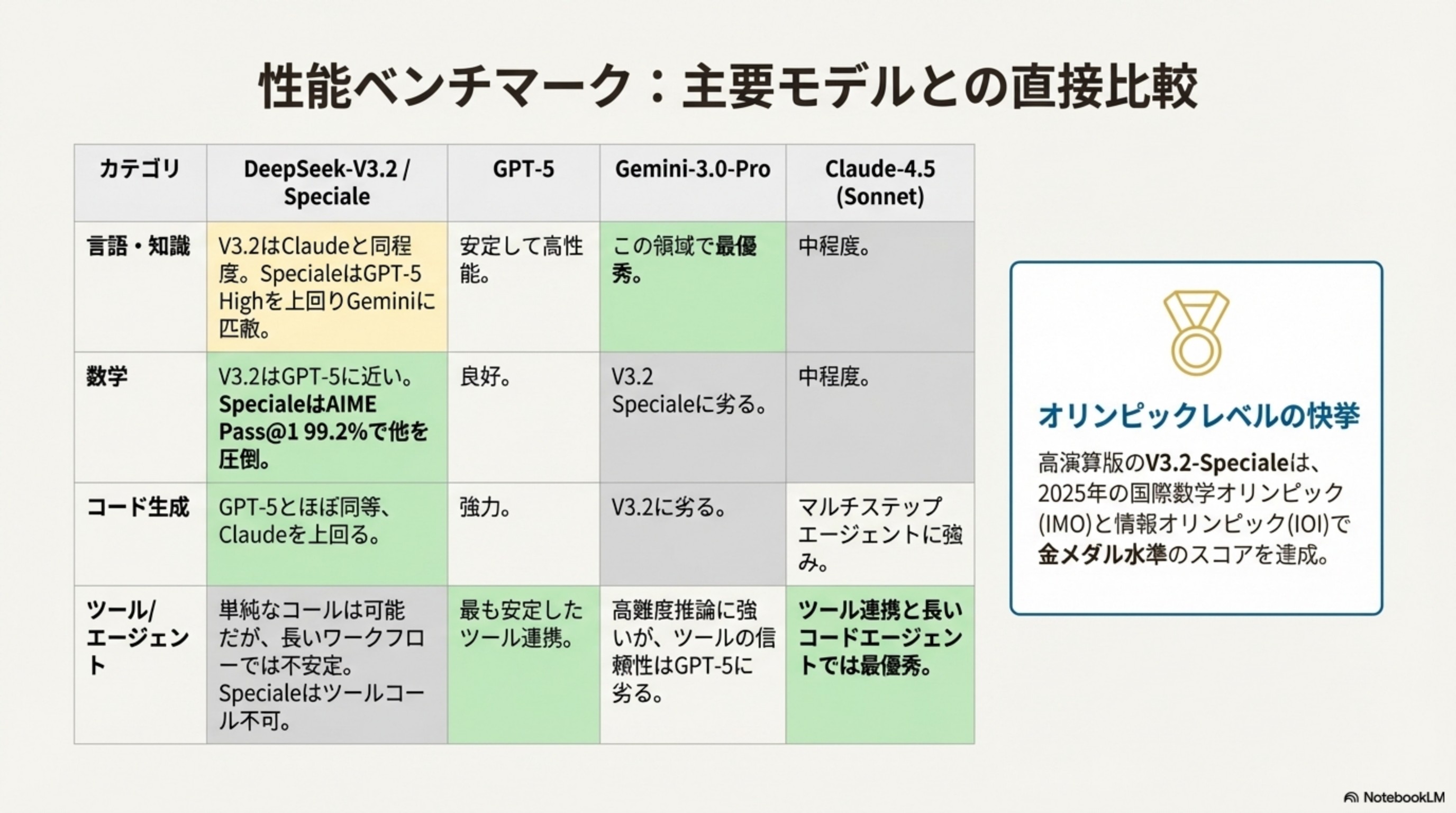
さらに「思考モード」を統合し、ツール使用と自律的な問題解決をシームレスに実行。特化型モデル「Speciale」は数学・情報オリンピック金メダル級の性能を誇ります。
ニュースのハイライト
【圧倒的なコストパフォーマンス】
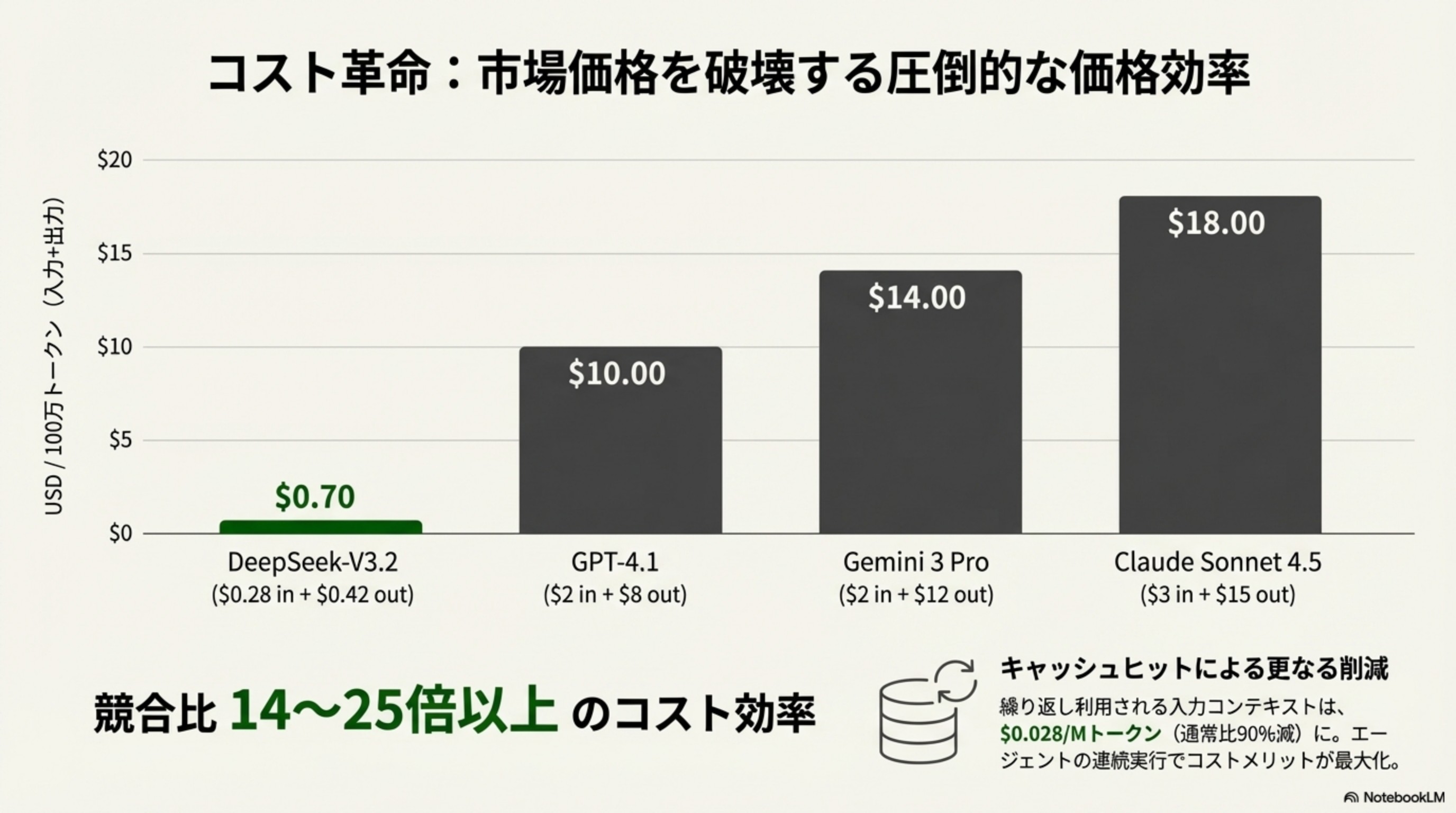
DeepSeek-V3.2は、性能を維持しつつ長文処理コストを大幅に改善しました。キャッシュヒット時の入力トークン単価は100万トークンあたり$0.028と、同等性能の他社モデルと比較して14〜25倍以上安い水準を実現。オープンソース(MITライセンス)としても公開され、開発者に新たな可能性を提供します。
主な新機能と特徴
DeepSeek-V3.2には、アーキテクチャの革新から新機能の統合まで、多くの強化点があります。
3つの革新ポイント
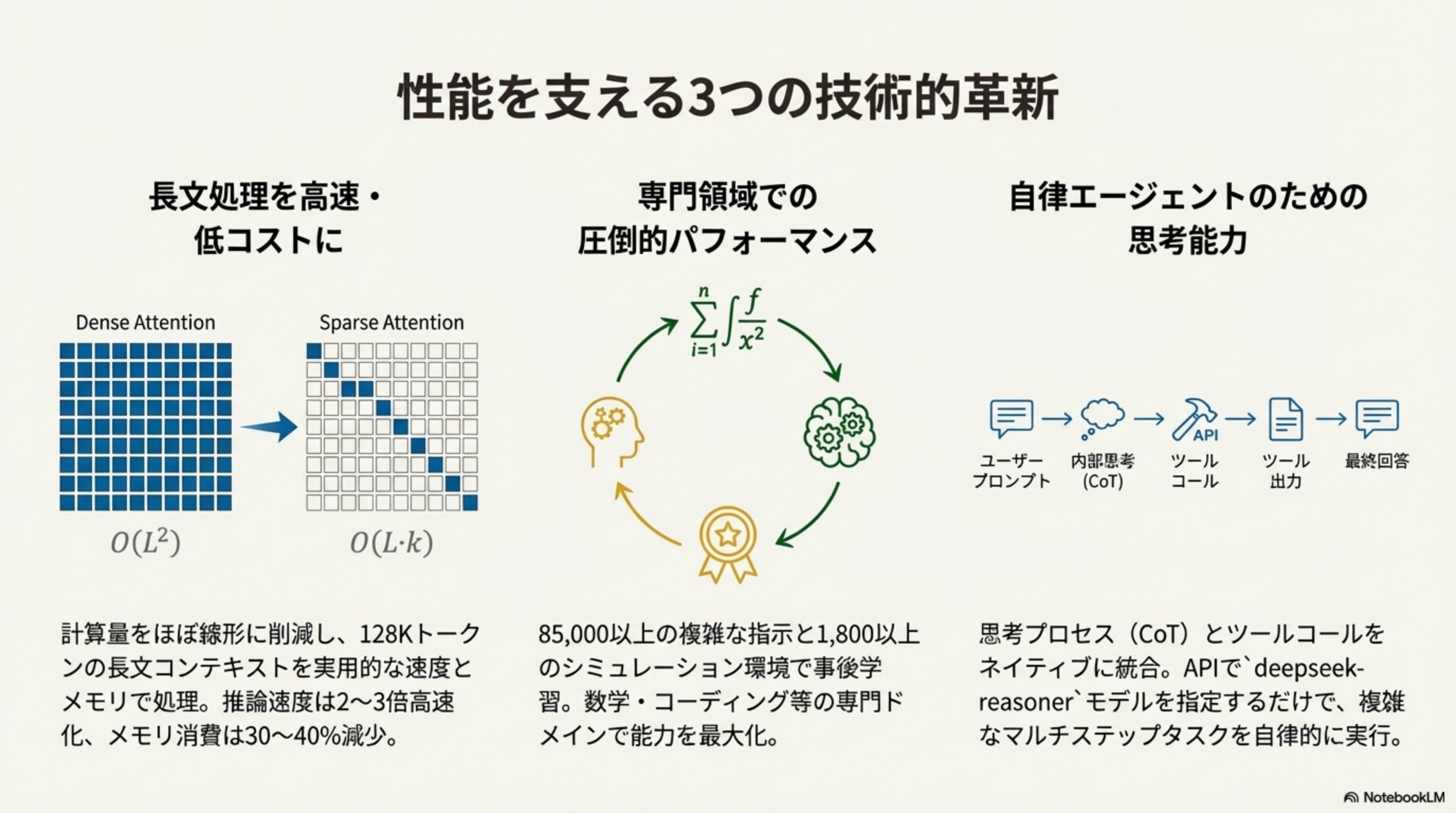
長文処理の革命 (DSA)
スパース注意機構(DSA)により計算量を削減。128Kトークン(小説1冊分)を高速・低メモリで処理し、生成速度は秒間60トークンに達します。
思考モードの統合
推論しながらツールを使用する能力を統合。コード実行や検索を自律的に行い、複雑なタスクを解決します。新たな役割 `developer` も追加。
Speciale & コスト
推論特化版「Speciale」はGPT-5やGemini 3.0 Proに匹敵する性能。それでいて圧倒的な低コストとオープンソース化を実現しました。
今後の展望
DeepSeek-V3.2は、長文ログ解析、大規模コードベースの処理、長期記憶を持つチャットボット、そして自律エージェントシステムなど、コストと性能の両立が求められる分野での活用が期待されます。オープンな重み公開により、コミュニティ主導のイノベーションも加速するでしょう。
スライド資料 (全ページ)